クラウドではじめるデータマネジメント
データウェアハウス or データレイクハウス?その判断基準は?
データウェアハウス or データレイクハウス?その判断基準は?



本コンテンツは、当社が執筆している「実践DX、クラウドで始めるデータマネジメント 第6回「データレイクハウスも登場、クラウドで進化するDWHとデータマネジメントの関係」の内容を一部要約しつつ独自コンテンツを加えたものです。日経クロステック記事の全文はこちらをご覧ください。
目次
この記事は、データ分析に利用されるデータウェアハウスとデータレイクハウスの基本概念、相違点、ビジネスへの適合性に焦点を当てて概観します。データレイクハウスが注目される理由と選定にあたっての注意点をご理解いただけます。
データウェアハウスの基礎知識
「データドリブン」「データの民主化」という表現がビジネスの場面で頻繁に出現するようになりました。これは、多様な経済活動から収集されたデータを解析し、重要な洞察を得ることで、データに基づいたスピーディーで質の高い意思決定が可能になることを意味します。「DMBOK2」という知識体系において、データウェアハウス(DWH)とビジネスインテリジェンス(BI)の領域に当たります。ここでは、特に「データウェアハウス」にスポットを当て、その重要性と活用方法について掘り下げます。
前回では、データとシステムの増加に伴う複雑さに対処する一つの方法として「データレイクを活用したアーキテクチャの採用」について紹介しました。データウェアハウスはデータレイクに溜まっているデータを取り込んで分析や意思決定に利用します。データウェアハウスを活用して効果的な意思決定を行うには、データがバラバラになっておらず、適切に統合されている必要があります。データウェアハウスとデータレイクはとても近しい関係にあるため、アーキテクチャを設計する際はセットで検討するケースが多くあります。そして、データウェアハウスとデータレイクを実際にセットにしたものが「データレイクハウス」です。
前半で「データウェアハウス」の特徴などの基礎知識について説明し、後半では、短期間に進化を遂げているデータレイクハウスの革新性について触れています。
※データマネジメント業務では、データレイクとデータウェアハウスのような「業務的に関連性の強い領域」が頻繁に見られます。データ活用の際は、データマネジメントの各領域について理解を深め、自社の業務全体として、実行しやすくコストを抑えられるサービスやアーキテクチャを検討・選択することが重要です。
データウエアハウスの特徴
データウェアハウスは、多様なデータソースから集められた情報を集中的に保管するための大型データベースシステムです。このシステムは分析やレポート作成に使用されます。その基礎となる技術はリレーショナルデータベース(RDB)であり、実際にRDBを発展させて開発されてきた歴史があります。通常の業務システムでもRDBが使われることは一般的ですが、データウェアハウス専用のRDBは次のような特徴を持っています。
列指向
RDBが1件のまとまった最小データ単位である行単位でデータを保管するのに対して、データウェアハウスでは列単位でデータを保管します。列単位というのは、たとえば顧客データの「都道府県」をひとまとまりにして保管するということです。これを列指向と呼びます。
列指向のデータベースは、大規模データの効率的な保管に適しています。さきほどの都道府県を例に取ると、都道府県の数は少ないため、データウェアハウスの内部では「東京都」を「1」に置き換えるなどして大幅に圧縮できるからです。圧縮することで分析対象のデータが少なくなるので、分析処理にかかる時間が短縮する効果もあります。列指向というのはデータウェアハウスのような大規模なデータ分析のコストとパフォーマンスを両立するキーとなる技術です。この技術自体はクラウドが登場するかなり前からデータウェアハウス製品に実装されているもので、目新しいものではありません。
並列処理
大規模データの集計・分析を高いパフォーマンスで処理できるよう、複数のノードで並列に処理できるようなクラスター構成を採れるようになっています。ノードの数を増やすことでパフォーマンスを高めることが可能で、データ量やユーザ数が増えた場合、ノード数を増やして並列処理の処理能力を拡張できることが強みです。半面、軽量かつ大量のトランザクション処理や、更新処理は苦手です。
分析機能
集計・分析のための関数や機能が強化されているものが多いです。多次元での分析や特定用途向けの集計済みデータをデータマート領域に格納するといった使い方ができます。但し、通常のRDBも機能が増えてきているため、差はかなり小さなものになっています。
データウェアハウスをクラウドで構築する最大の利点
データウエアハウスをクラウド上で運用する最大の利点は「コスト効率の良さ」にあります。クラウドサービスでは使用した分だけ料金を支払う従量課金制が一般的です。データウエアハウスは分析処理を行う時間帯に大量のコンピューティングリソースを必要としますが、その他の時間帯はリソース消費が大幅に減少します。このような使用量の変動に対応する場合、オンプレミスの固定的なコスト構造よりも従量課金制の方が経済的です。
1TB以上のデータセットを高速に分析したい場合、オンプレミスでハードウェアを購入して運用すると初期導入費用が2,000万円~1億円以上、年間の保守費用が1,000万円以上という相場観でした(事例数が多いパターンの概算。諸条件によって異なる)。クラウドでは、初期導入費用が数百万円、年間費用も数百万程度と大きく下がる傾向です(コストを最適にするには適切な設計とコストシミュレーションが必要)。
また、データ量や利用者数の増加に応じてシステムの拡張が容易な点もクラウド利用の大きなメリットです。データウエアハウスの運用においては、特にクラウドの持つ柔軟性とコストパフォーマンスの高さが有効に働きます。
欠点を逆手に進化を遂げたデータレイクハウス
クラウド上の運用で、コスト面の利用ハードルが大きく低下したデータウェアハウスですが、運用面では問題が残されています。データウエアハウスの運用で特に工数がかかるのがデータの統合作業です。「データレイク」を活用することでデータ連携のルートを減らすことが可能ですが、デジタルトランスフォーメーション(DX)の進展に伴い、分析対象となるデータや軸が増えるため、結果的には連携・統合作業が増加します。これによりデータエンジニアのリソースが圧迫され、データ活用の前進が妨げられてしまうことがあります。「データ連携の効率化」は多様なデータを扱う組織にとって重要な検討事項です。
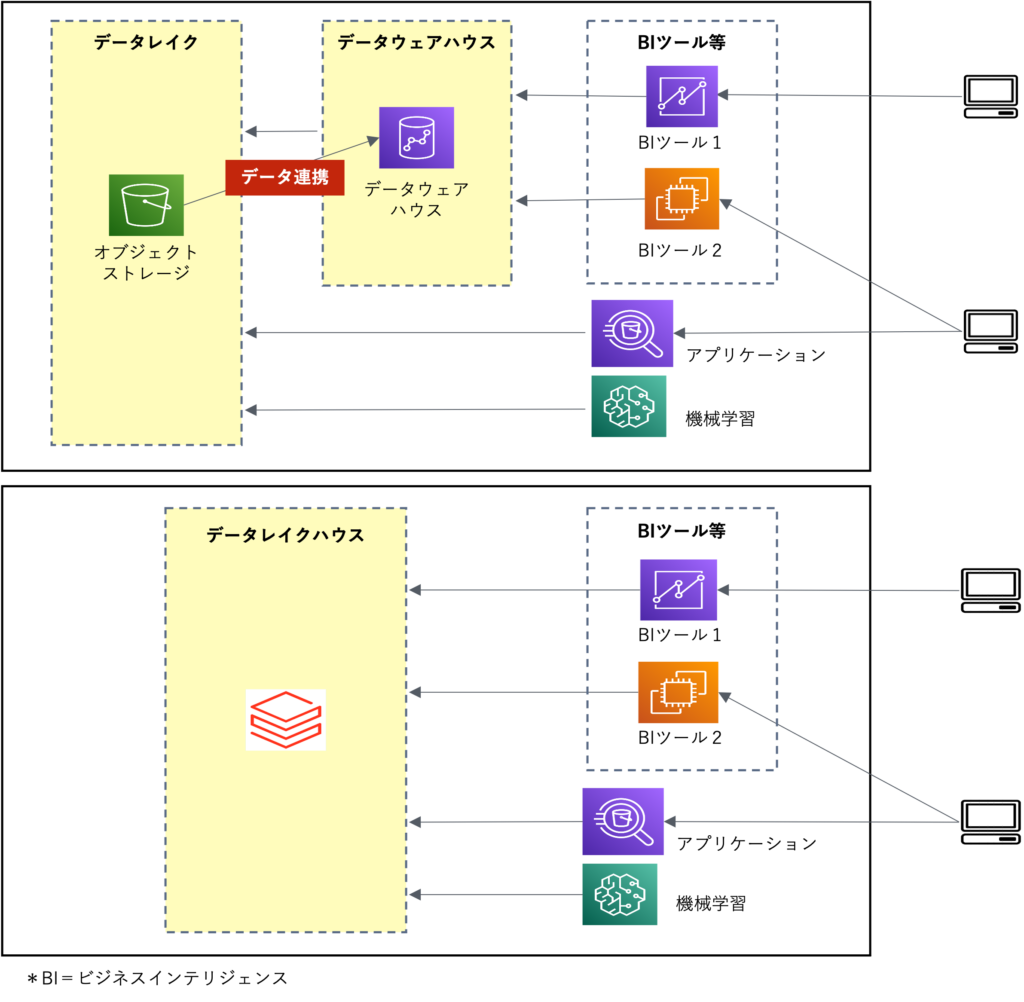
データウエアハウスとデータレイクの利点を融合。
データ連携が不要な「データレイクハウス」
クラウドでは、データ連携そのものを不要にする新しいアーキテクチャが登場しています。その一つが「データレイクハウス」です。データウエアハウスとデータレイクの利点を融合したアーキテクチャで、製品によっては「データレイクハウス」や「レイクハウス」、「データプラットフォーム」などと呼ばれます。
これらには共通の特徴があり、データレイク上で統合されたデータを直接利用できるため、従来のデータ連携の工数を削減できます。また、統合データはBIや機械学習、データサイエンスなど多様な用途で使用できます。
このアーキテクチャでは、コンピューティングとストレージが分離されており、処理に必要なリソースは利用時に割り当てられ、終了後に解放されます。プロビジョニングはクラウド内で自動的に実行され、利用者はリソースの上限設定のみを行います。
データウェアハウス、データレイクハウスの主なサービス
データウェアハウス、データレイクハウスの主なサービスには次のようなものがあります。
データウエアハウス
Google BigQuery
Google BigQueryは、Google Cloud Platformが提供するフルマネージド型のデータウェアハウスサービスです。BigQueryはサーバーレスで、ユーザーはサーバーの管理やスケーリングに関する心配をせずにデータ分析に集中できます。
料金体系は柔軟で、ストレージとクエリ処理に基づいて従量課金されます。クラウドでは、早くから従量課金で利用できるようになったデータウェアハウスサービスとして知られています。SQLベースのクエリ言語を採用しており、既存のSQL知識を活用してクエリを作成できます。
BigQueryは、データ分析に加えて、機械学習にも利用できる他、GA4やYoutubeなどのGoogleのサービスと連携してログを自動取り込みするなどの機能が追加されています。
Amazon Redshift
Amazon Redshiftは、Amazon Web Services(AWS)が提供するクラウドベースのデータウェアハウスサービスです。BigQueryと同様に、機械学習やAWS内の他のサービスとの連携機能が備わっています。サーバレスとサーバレスではないタイプから選択できるようになっており、使い方に応じて適したタイプを選んで利用します。従量課金への対応も進んでおりAWS既存ユーザに広く利用されています。
Azure Synapse Analytics
Azure Synapse Analyticsは、マイクロソフトが提供する統合型の分析サービスです。他のサービスと異なるのは、データウェアハウスの機能に加えて、データの収集と統合(ETLに相当する機能)、Apache Spark(大規模データの一括変換などの用途に利用)を融合させたプラットフォームであるということです。多くの機能を包含しており、1つのサービスで複数の役割を実行することができます。
使用するリソースに応じて課金される従量課金、サーバレス、機械学習機能があることなどは他クラウドサービスに似ています。
データレイクハウス
次に、データレイクハウスの主なサービスを説明します。サービスごとの詳しい説明は別の記事にて掲載します。
Snowflake
Snowflakeは、データレイクハウスの代表的なサービスの1つとして知られており、導入社数が増えています。クラウドネイティブなサービスで次の特徴があります。
・従量課金制
・コンピューティングリソースとストレージリソースを独立してスケーリングでき、データ量やクエリの複雑性に応じてリソースを調整可能
・上記のリソース調整(プロビジョニングといいます)をはじめ、運用の一部が自動化されている
・データレイクハウスとして、データレイクからのデータ連携負担が非常に小さい
加えて、クラウドプロバイダー(AWS、Azure、Google Cloud Platformなど)の環境に依存しないことも特徴です。Snowflake自体はサードパーティーのサービスとして、どのクラウドプロバイダー上で動作させるかを選択します。クラウドプロバイダー独自のデータウェアハウスサービスと大きく異なることは、主要クラウドプロバイダー上でも動かすことができるという点です。複数のクラウドプロバイダーを併用するマルチクラウドが浸透していく中で、どの環境でも動作させることができるという特徴が生きる場面が出てきます。
データ共有の機能も備わっています。外部のビジネスパートナーとデータ共有したい場合(自社データの分析をデータサイエンスの専門家に委託する場合など)に、Snowflakeであれば共有対象のデータセットと共有先を指定することで自動的にデータが共有される仕組みがあります。
Databricks
DatabricksもSnowflakeと同様に、データレイクハウスの代表的なサービスとして知られています。やはり、クラウドネイティブなサービスとして従量課金、柔軟なリソース管理、自動的なプロビジョニングなどの特徴を持っており、データレイクハウスとしてデータ連携負担が非常に小さいです。
サードパーティーのサービスであり、クラウドプロバイダーに依存せず、利用者がどのクラウドプロバイダー上で使うかを選ぶことができます。この点についてDatabricksがユニークなのは、サードパーティーのサービスでありつつ、クラウドプロバイダー上のサービスにもなっていることです。Azure、Google Cloudでは、コンソールのメニューからDatabricksを選んでデータレイクハウスを作成できます。サードパーティーのサービスであることと、クラウドプロバイダー上のサービスであることの両面を持っています。
当初は、Apache Sparkの機能に強く、ビッグデータ処理と機械学習といったデータレイクハウスサービスとしての強みがありました。その後、データエンジニアリング、データサイエンス、アプリケーション開発の機能を追加し、データウェアハウス用途に限らずデータ活用のプラットフォームとして利用できるよう成長しています。
データウェアハウス or データレイクハウス?その判断基準は?
データウェアハウスとデータレイクハウスは、初期にはデータウェアハウスとしての利便性を競争領域としていましたが、現在は開発や機械学習にも使える機能を揃えたプラットフォームとして利用できるように進化しています。
データウェアハウスの管理者・利用者はデータエンジニアやデータサイエンティストであるのに対し、プラットフォームとしてのデータレイクハウスの利用者にはアプリケーション開発者や機械学習エンジニアも加わります。
※競争領域の変化には、クラウドプロバイダーがデータレイクハウスとして利用できるサービスを強化したことも影響しています。
サービスを選択する際は、オールインワンのプラットフォームとして多様な属性の人が利用するかどうかというのが1つの観点になります。その他、本記事で取り上げた特徴を自社で生かす場面があるかについて検討すると良いでしょう。コストは使い方によって有利不利が変わるため、利用シナリオを想定したうえで比較することをお勧めします。
このように、データウェアハウスとデータレイクハウスの競争領域は短い間にスピーディに変化しています。今後も新たな特徴を獲得したり、新たなサービスが生まれたりすると考えられます。最新の情報を入手し、選択時の判断材料の1つとしてお役に立てると幸いです。
上記の他、データウェアハウスの運用スタイルは、クラウドになることで大きく変わる点があります。詳しくは日経クロステック記事に記載していますので、ご興味ありましたら読んでいただければと思います。
次回のテーマは「データ収集」です。外部データ活用が進む現状とデータマネジメント組織の役割について説明します。
























